

AI天团出道已久,成员都是集颜值和才华于一身的男纸,之前我们已经见过其中三位了,压轴出场的到底是谁?
更为重要的是,他会带给我们关于人工智能的什么新鲜东东呢?

王宇航,博士毕业于中国科学院自动化研究所,现阶段主要研究方向包括:深度学习、图像语义分割、目标检测、网络模型压缩与加速等。
宇航告诉我们,深度神经网络也可以是一个“Transformer”,它可以在使用时根据输入数据动态地调整自己的结构。至于为什么要设计这样的网络结构,宇航用“杀鸡焉用牛刀”来形容它。
随着近年来深度学习的快速发展,我们已经能够获得越来越精确的模型实现对图像目标的识别,而相应地,模型的体积也在成倍地增长,这给模型的部署和应用带来了很大的麻烦。因此,很多学者一直致力于给深度神经网络模型“减重”,从而实现效果和速度的平衡。
其中的主要方法包括对模型和知识进行蒸馏,对模型进行剪枝,以及对模型参数进行分解和量化等等。这些方法都能够提高模型中“有效计算”的密度,从而使模型变得更加高效。如果说这些方法是获得了更加高效的“静态”模型的话,另一类方法则采用“动态”的模型来提高应用端的计算效率,它们针对不同的输入数据动态地调整网络的前向过程,去除不必要的计算,从而达到加速的目的。
今天王宇航博士要介绍的是两篇使用“动态”的网络结构来实现CNN模型加速的文章,先注明一下来源~
1.Runtime Neural Pruning,原文链接:https://papers.nips.cc/paper/6813-runtime-neural-pruning,NIPS2017接收文章,来自清华大学。
2.SkipNet: Learning Dynamic Routing in Convolutional Networks,原文链接:https://arxiv.org/abs/1711.09485,来自UC Berkeley和南京大学。
首先,我们可以分析一下深度神经网络模型在训练和预测过程中的不同:在训练的过程中,我们要求模型对来自不同场景不同类别的目标都进行学习和辨别,以丰富其“知识储备”,并因此不得不引入更多的神经元和网络连接。
而在预测阶段,我们的需求往往集中于个体图像的识别,而应对这样相对单一的场景和目标,往往不需要我们使出全部的“看家本领”,只需要使用一部分相关知识针对性地去解决就可以了。
对于深度神经网络模型,参数,或者说神经元之间的连接,就是它的“知识”,而针对不同的数据对网络连接进行选择, 就可以动态地调整网络的计算过程,对于比较容易辨认的图像进行较少的编码和计算,而对于比较难以辨认的图像进行较多的编码和计算,从而提高网络预测的整体效率。
本文介绍的这两篇文章都是基于这样的出发点,而它们的关注点又各自不同。
“Runtime” 一文主要关注于减少网络中卷积层的channel数量,如下图所示:
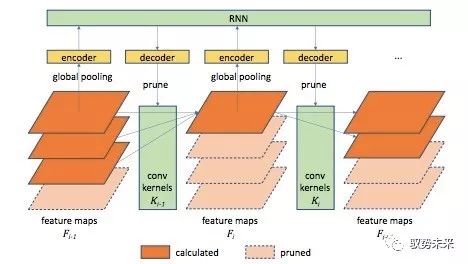
为了简化模型,他们将网络中每一个卷积层的卷积核分为k组,根据网络各前层的输出特征决定在本层中使用的卷积核数量m(1≤m≤k),并仅使用前m组卷积核参与运算,从而通过减小m来削减层与层之间的连接,达到channel pruning的效果。
而 “SkipNet”一文则主要关注网络中layer的数量,其主要思想如下图所示:
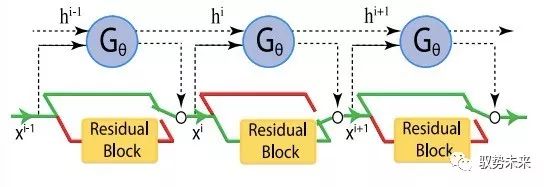
他们为网络中的每一个层(或每一组层)学习一个“门”,并基于网络各前层的输出特征进行判断,是将前一层输出的特征图输入本层进行计算还是直接越过本层将其送入后续网络,从而通过“skip”掉尽可能多的层来实现加速的目的。
从直观上来讲,这两篇文章分别从动态削减模型的“宽度”和“深度”的角度,实现了对预测过程中网络计算的约减。
那么如何实现对网络连接方式的动态调整呢?
在网络由浅至深的过程中,对于网络中每一层连接方式的选择(对于“Runtime” 一文是选择该层使用的卷积核数量,而对于 “SkipNet”一文是选择该层参与计算与否)可以看作一个序列决策过程,因此,这两篇文章均选择了强化学习的方式建模这一过程。将原始的主体CNN网络作为“Environment”,学习一个额外的轻量的CNN或RNN网络作为“Agent”来产生决策序列。其中,对于原CNN网络每一层的决策,作为一个“Action”都将带来相应的“Reward”。
为了在最大限度地压缩网络计算的同时最大化网络的分类精度,在构建“Reward”函数的过程中,需要同时考虑两个部分:1.对“Action”约减计算量的奖励,即prune掉的channel越多或skip掉的layer越多,获得奖励越大;2.网络最终的分类预测损失,即最终分类预测的log损失越小,获得奖励越大。由于这两部分的梯度计算方式不同,因此在对模型目标函数进行优化的过程中,会构成一个“强化学习+监督学习”的混合学习框架。
在具体的算法实现中,这两篇文章对于“Reward”函数的设计和优化策略的选择各有不同。“Runtime”一文采取了交替更新的方式,而“SkipNet”一文则采用了混合优化的方式,具体的细节我们就不在这里详述了。
对于方法的效果,这两篇文章都给出了严谨的数据对比和可视化结果分析,大家可以根据兴趣进行更深入的阅读和研究。而动态网络结构的意义,可能也不止于单纯的约减计算。网络连接的改变实际上影响着整个特征编码的过程,以“SkipNet”为例,对n个网络层的选择可能会带来2^n种不同的特征编码方式,而在训练这种动态选择策略的过程中,可能也会一定程度地解耦层与层之间的依赖关系,这也会为我们日后设计更具“自适应性”的网络结构和研究网络中信息的传递及融合方式带来更多的启发。





 扫一扫关注微信
扫一扫关注微信